tags:
- OS
- Processing The Processes
第一课 Processes
1.1 节内容了解即可,你需要知道什么是程序段、ELF 文件是什么。
1.1 Program and Process
A process is a program in execution.
你对进程这个词可能会陌生,但是你一定不陌生程序和文件这两个词。我们知道程序可以运行在机器上,而文件则是以一定格式存放数据的地方。要生成一个进程,我们需要先将程序交给操作系统,让操作系统帮我们运行。我们把这样具有一定格式的程序文件称为可执行文件。
1.1.1 Executable Files
我们这里所说的程序并不是高级语言源程序。高级语言源程序是给人类看的,计算机并不认识这些 ASCII 字符代表什么含义。在使用 C 语言的情况下,我们需要预处理、编译、汇编、链接之后才能得到可执行文件。且在不同的操作系统中,使用的可执行文件格式可能是不同的。
在 Linux 系统中,最常见的可执行文件格式是 ELF(Executable and Linkable Format) 。ELF 格式非常灵活,支持静态链接、动态链接、可重定位代码等多种特性。它不仅用于可执行文件,还用于共享库和核心转储文件。
而在Windows系统中,标准的可执行文件格式是 .exe ,这是 "executable" 的缩写,可能也是我们见的最多的可执行文件的格式。除了 .exe 格式,Windows 还使用其他格式,如 .dll(动态链接库)和 .sys(系统驱动程序)。
1.1.2 ELF Layout (x64)
我们说文件是具有一定格式的数据集合。ELF 文件有两种视图:链接视图和可执行视图,前者指链接之前的 ELF 目标文件,后者是指链接完成之后的 ELF 目标文件。二者最主要的区别在于,链接前的 ELF 目标文件无法直接载入内存中执行;而通过链接,ELF 目标文件中的地址确定之后(虚拟地址),就可以载入内存中运行了。
在后续的小节中,我们用下面的程序做例子:
#include <stdio.h>
int main(){
printf("hello, world\n");
}
我们用命令将程序生成可重定位目标文件和可执行目标文件:
gcc -c hello.c -o hello.o
gcc hello.c -o hello
1.1.3 ELF: Relocatable File
在ELF文件的可重定位视图中,目标文件由 ELF 头、程序头表(可选)、节(Sections)、和节头表组成。节(section)是ELF文件中具有相同特征的最小可处理单位,链接时就是对相同的属性的节进行组合成段(segments),最后加载器会按段把 ELF 文件加载进内存。
1.1.3.1 ELF Header
ELF 头位于 ELF 文件最开始的地方(偏移为0),包含了文件结构的说明信息。ELF64 头信息在机器中的编码是 01 序列,我们可以通过readelf 这种工具软件来查看 ELF 中包含的信息。这里我们需要读取文件的头信息,我们用 readelf -h hello.o 来获取ELF的头包含什么信息。
du@DVM:~/Desktop$ readelf -h hello.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 600 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 14
Section header string table index: 13
hello.o 是可重定位的目标文件,这里给出的是 ELF 的链接视图,所以装入的入口地址是 0x0。此时,hello.o 程序是无法执行的。
1.1.3.2 Program Header Table
程序头表主要在程序的加载阶段使用。链接阶段主要关注的是节和节头表。程序头表我们保留,在学习 ELF 的可执行视图时进行介绍。
1.1.3.3 Sections and Section Header Table
我们前面在ELF头中其实都看到hello.o 中有多少个节头了。这些节头给出每个节的相关信息,如节的名称、节的起始地址、节的偏移等等。每个节承担不同的功能,我们很快就能根据这些信息从文件的二进值信息这找到我们写进去的数据了。
节头表是一个结构体,包含了每个节的信息。在ELF头中,我们看到一个节头的大小是64字节,节头的结构体定义如下:
typedef struct {
uint32_t sh_name; // 节名称的索引
uint32_t sh_type; // 节的类型
uint64_t sh_flags; // 节的标志(在虚拟空间中的访问属性)
uint64_t sh_addr; // 节的虚拟内存地址(链接视图无意义)
uint64_t sh_offset; // 节在文件中的偏移
uint64_t sh_size; // 节的大小
uint32_t sh_link; // 节的链接信息
uint32_t sh_info; // 链接信息
uint64_t sh_addralign; // 对齐要求信息
uint64_t sh_entsize; // 节中条目的大小
} Elf64_Shdr;
节头的结构体中的数据都是01序列,所以我们用 readelf -S 命令来获取节头表的信息:
du@DVM:~/Desktop$ readelf -S hello.o
There are 14 section headers, starting at offset 0x258:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
000000000000001e 0000000000000000 AX 0 0 1
[ 2] .rela.text RELA 0000000000000000 00000198
0000000000000030 0000000000000018 I 11 1 8
[ 3] .data PROGBITS 0000000000000000 0000005e
0000000000000000 0000000000000000 WA 0 0 1
[ 4] .bss NOBITS 0000000000000000 0000005e
0000000000000000 0000000000000000 WA 0 0 1
[ 5] .rodata PROGBITS 0000000000000000 0000005e
000000000000000d 0000000000000000 A 0 0 1
[ 6] .comment PROGBITS 0000000000000000 0000006b
000000000000002c 0000000000000001 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 0000000000000000 00000097
0000000000000000 0000000000000000 0 0 1
[ 8] .note.gnu.pr[...] NOTE 0000000000000000 00000098
0000000000000020 0000000000000000 A 0 0 8
[ 9] .eh_frame PROGBITS 0000000000000000 000000b8
0000000000000038 0000000000000000 A 0 0 8
[10] .rela.eh_frame RELA 0000000000000000 000001c8
0000000000000018 0000000000000018 I 11 9 8
[11] .symtab SYMTAB 0000000000000000 000000f0
0000000000000090 0000000000000018 12 4 8
[12] .strtab STRTAB 0000000000000000 00000180
0000000000000013 0000000000000000 0 0 1
[13] .shstrtab STRTAB 0000000000000000 000001e0
0000000000000074 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), l (large), p (processor specific)
现在,我们就能准确地从中知道每个节相对 base 的确切位置。但仍然迷惑的是为何所有节的地址字段都为 0x0000 ?这是因为当前 hello.o 并没有链接重定位生成可执行目标文件,所以对应的每个节的起始地址都为 0x0(因为这时的节地址是毫无意义的)。
1.1.3.4 File Structure Layout
通过节头表中的信息和ELF头的信息,我们就能绘制出 hello.o 文件结构。其结构如下:
+-------------------------+-------------------------+ 0x000
| ELF Header | 64 bytes (0x40) |
+-------------------------+-------------------------+ 0x040
| .text | 30 bytes (0x1e) |
+-------------------------+-------------------------+ 0x05e
| .data | 0 bytes |
+-------------------------+-------------------------+ 0x05e
| .bss | 0 bytes |
+-------------------------+-------------------------+ 0x05e
| .rodata | 13 bytes (0x0d) |
+-------------------------+-------------------------+ 0x06b
| .comment | 44 bytes (0x2c) |
+-------------------------+-------------------------+ 0x097
| .note.GNU-stack | 0 bytes |
+-------------------------+-------------------------+ 0x097
+-------------------------+-------------------------+ 0x098(0x97对齐)
| .note.gnu.property | 32 bytes (0x20) |
+-------------------------+-------------------------+ 0x0b8
| .eh_frame | 56 bytes (0x38) |
+-------------------------+-------------------------+ 0x0f0
| .symtab | 144 bytes (0x90) |
+-------------------------+-------------------------+ 0x180
| .strtab | 19 bytes (0x13) |
+-------------------------+-------------------------+ 0x193
+-------------------------+-------------------------+ 0x198(0x193对齐)
| .rela.text | 48 bytes (0x30) |
+-------------------------+-------------------------+ 0x1c8
| .rela.eh_frame | 24 bytes (0x18) |
+-------------------------+-------------------------+ 0x1e0
| .shstrtab | 116 bytes (0x74) |
+-------------------------+-------------------------+ 0x254(596 Bytes)
+-------------------------+-------------------------+ 0x258(600 Bytes)
| Section Headers | 896 bytes (14 * 64) |
+-------------------------+-------------------------+ 0x5d8(600+896 Bytes)
通过结构信息,我们可以很清楚地看到文件从哪开始,从哪里结束。我们用 hexdump -C 以16进制和 ASCII 格式查看 hello.o 文件。我们看到,程序如我们预想的一样从 0x5d8 结束。查看 .rodata 节的位置,我们也如预料地看到了 hello,world. 这样12个字符。至此,关于 hello.o的解读圆满结束!
du@DVM:~/Desktop$ hexdump -C hello.o
00000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 |.ELF............|
...
00000050 89 c7 e8 00 00 00 00 b8 00 00 00 00 5d c3 68 65 |............].he|
00000060 6c 6c 6f 2c 20 77 6f 72 6c 64 00 00 47 43 43 3a |llo, world..GCC:|
...
000005d0 00 00 00 00 00 00 00 00 |........|
000005d8
1.1.4 ELF: Position-Independent Executable File
既然本阶段和进程有关,我们就聚焦于 ELF 的可执行目标文件视图上。链接后,可重定位目标文件进行相同属性节合并成段。由于在程序加载时是按段为单位进行加载,所以可执行目标文件由 ELF 头、程序头表、段(Segments)、节、和节头表组成,新加入了段的概念。
1.1.4.1 ELF Header
我们先用命令 readelf -h 查看ELF头,看看与可重定位目标文件有什么不同。首先,最大的不同就是程序的入口地址不再是0了,还多了程序头表还有节的数量变多了。然后我们发现,在链接(重定位)过后,我们少了带重定位信息的节(如 .rela.text 、.rela.data 等)。
du@DVM:~/Desktop$ readelf -h hello
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Position-Independent Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x1060
Start of program headers: 64 (bytes into file)
Start of section headers: 13976 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 13
Size of section headers: 64 (bytes)
Number of section headers: 31
Section header string table index: 30
1.1.4.2 Program Header Table
我们从ELF头中并没有找到什么关于段和段头表的信息,它们在哪里呢?这些信息就存储在程序头中。在ELF头中,我们能读取到程序头的大小和数量,每个程序头描述了一个段的信息。所以,一个个的程序头实际上就是一个个的段头。
和节头一样,段头也是一个结构体数组,段头表用于描述这些段的各种属性信息。从上面的ELF头信息中我们可以读出,程序有13个段头,每个段头有56个字节。
typedef struct {
uint32_t p_type; // 段的类型
uint32_t p_flags; // 段的权限标志
uint64_t p_offset; // 段在文件中的偏移量
uint64_t p_vaddr; // 段在内存中的虚拟地址
uint64_t p_paddr; // 段在内存中的物理地址
uint64_t p_filesz; // 段在文件中的大小
uint64_t p_memsz; // 段在内存中的大小
uint64_t p_align; // 段在内存中的对齐要求
} Elf64_Phdr;
程序头表描述了从文件中加载的各个段(segment) 的属性和位置,这些信息对于系统加载器将程序加载到内存并执行至关重要。每个Program Header描述了一个或多个段(segment),包括它们在文件中的位置和大小、应当被加载到内存中的位置、以及需要的内存权限(如只读、可读写等)。
我们用 readelf -l 读取段头表的信息:
du@DVM:~/Desktop$ readelf -l hello
Elf file type is DYN (Position-Independent Executable file)
Entry point 0x1060
There are 13 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000000040 0x0000000000000040
0x00000000000002d8 0x00000000000002d8 R 0x8
INTERP 0x0000000000000318 0x0000000000000318 0x0000000000000318
0x000000000000001c 0x000000000000001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000628 0x0000000000000628 R 0x1000
LOAD 0x0000000000001000 0x0000000000001000 0x0000000000001000
0x0000000000000175 0x0000000000000175 R E 0x1000
LOAD 0x0000000000002000 0x0000000000002000 0x0000000000002000
0x00000000000000f4 0x00000000000000f4 R 0x1000
LOAD 0x0000000000002db8 0x0000000000003db8 0x0000000000003db8
0x0000000000000258 0x0000000000000260 RW 0x1000
DYNAMIC 0x0000000000002dc8 0x0000000000003dc8 0x0000000000003dc8
0x00000000000001f0 0x00000000000001f0 RW 0x8
NOTE 0x0000000000000338 0x0000000000000338 0x0000000000000338
0x0000000000000030 0x0000000000000030 R 0x8
NOTE 0x0000000000000368 0x0000000000000368 0x0000000000000368
0x0000000000000044 0x0000000000000044 R 0x4
GNU_PROPERTY 0x0000000000000338 0x0000000000000338 0x0000000000000338
0x0000000000000030 0x0000000000000030 R 0x8
GNU_EH_FRAME 0x0000000000002014 0x0000000000002014 0x0000000000002014
0x0000000000000034 0x0000000000000034 R 0x4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 0x10
GNU_RELRO 0x0000000000002db8 0x0000000000003db8 0x0000000000003db8
0x0000000000000248 0x0000000000000248 R 0x1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.gnu.property .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt
03 .init .plt .plt.got .plt.sec .text .fini
04 .rodata .eh_frame_hdr .eh_frame
05 .init_array .fini_array .dynamic .got .data .bss
06 .dynamic
07 .note.gnu.property
08 .note.gnu.build-id .note.ABI-tag
09 .note.gnu.property
10 .eh_frame_hdr
11
12 .init_array .fini_array .dynamic .got
通过 Section to Segment mapping 中的信息,我们能够知道各个段和其所包含的节之间的映射关系,哪个段由哪些节组成。并且通过段的类型能够知道哪些段是需要载入内存,与存储器进行映像的。通过这些段头的信息,和在上节课的操作一样,我们可以通过这些地址信息找到我们只读字符串的位置。
00002000 01 00 02 00 68 65 6c 6c 6f 2c 20 77 6f 72 6c 64 |....hello, world|
00002010 00 00 00 00 01 1b 03 3b 30 00 00 00 05 00 00 00 |.......;0.......|
1.2 Program Loading
当 ELF 程序加载进内存时,我们就说一个新的进程诞生了。当我们请求操作系统运行一个程序(如 ELF 可执行文件)时,操作系统会完成以下步骤:
- 读取文件:操作系统读取存储在磁盘上的 ELF 可执行文件。
- 创建进程:操作系统调用创建新进程的系统调用(如
fork或exec),此时会分配并初始化PCB。PCB包含进程的基本信息,如进程ID、状态、优先级、程序计数器、寄存器信息等。 - 解析Program Header Table:系统解析Program Header以确定文件的哪些部分需要被加载到内存,它们需要被加载到内存的什么位置,以及需要什么权限(只读、读写、执行)。
- 内存分配:操作系统为程序的各个段分配内存。这通常涉及到为代码段、数据段和BSS段分配空间,同时也包括为动态链接库和程序运行时堆栈的初始化预留空间。
- 加载到内存:将代码和数据从磁盘复制到内存中的预定位置。
- 程序执行:操作系统将控制权交给程序,从其入口点开始执行。
1.3 Process
简单地说,进程是运行程序的一个实例。相比于程序(包括指令和数据),进程还包含进程状态以及执行所需要的各项资源。也因此,我们称程序是静态的,而进程是动态的。进程是操作系统资源分配调度的基本单位,每个进程也都有自己独立的虚拟内存区域和其他的资源。
1.3.1 Process Control Block
当进程被创建,操作系统需要一个数据结构来跟踪并表示一个进程的信息和状态,我们通常将这个结构称作进程控制块。操作系统将进程的所有信息都存储在一个PCB中。在所有的现代操作系统中,每个进程都有一个与之对应的PCB,它用于存储关于该进程的全部信息,PCB 中包括:
- 进程标识符(Process Identifier, PID):这是一个整型,用于区分系统中的各个进程。
- 进程状态(State):它表示进程当前的状态,如就绪(ready)、运行(running)、等待(waiting)或终止(terminated)等。
- 程序计数器(Program Counter):存储下一条要执行的指令的地址。
- CPU寄存器信息(Register Data):保存进程执行状态需要的所有寄存器值,包括累加器、索引寄存器、栈指针等。
- CPU调度信息(Scheduling infos):包括进程优先级、调度队列指针等,用于CPU调度决策。
- 内存管理信息:包括指向进程页面表、内存限制、段表等的指针。
- 会计信息(Accounting Infomation):包括CPU使用时间、实际使用的时间和限制、进程创建的时间等。
- I/O 状态信息:包括分配给进程的I/O设备列表、打开文件列表等。
- ......
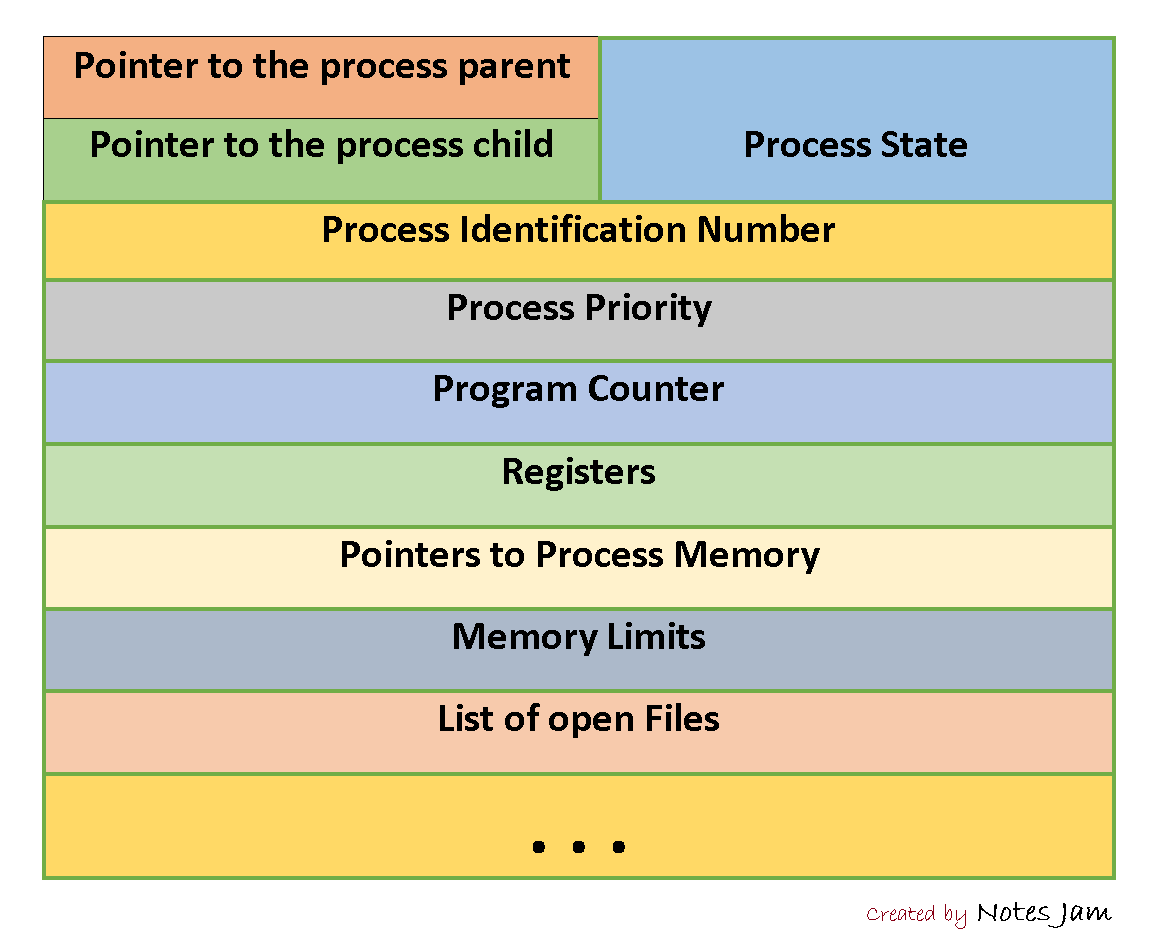
PCB是操作系统内核中的一个重要数据结构,用于存储与一个特定进程相关的所有信息。通过这些信息,操作系统可以有效地管理和调度进程,确保多任务环境下的进程并发执行和资源分配的合理性。操作系统每次对进程的操作都对应着对PCB的更新。
1.3.1.1 task_struct
在 Linux操作系统中,进程控制块在 task_struct 的 C 结构体中实现。task_struct 结构体位于内核源代码目录中的 <include/linux/sched.h> 头文件中。这个结构体包含了表示进程所需的所有信息,包括进程的状态、调度和内存管理信息、打开文件的列表,以及指向进程的父进程、子进程和兄弟进程的指针。
其中的一些字段有:
long state; /* state of the process */
struct sched entity se; /* scheduling information */
struct task struct *parent; /* this process’s parent */
struct list head children; /* this process’s children */
struct files struct *files; /* list of open files */
struct mm struct *mm; /* address space */
......
这其中,许多字段都和资源密不可分。
1.3.2 Virtual Memory
内存是进程运行所依赖的核心资源,其管理方式直接影响系统的稳定性和安全性。现代操作系统通过虚拟内存的机制对物理内存进行抽象,使得每个进程在运行时都认为自己独占一个连续、完整且私有的虚拟地址空间。
这就让运行时的进程所看到的一切都是虚拟的,即进程的所有地址空间都是操作系统提供给进程的抽象概念。凡是进程想要申请机器上的物理内存,都需要经过操作系统之手来进行统一的物理内存分配,返回以进程一段连续的虚拟内存地址。这种机制使得进程在运行时似乎有独立且完整的内存控制,而实际上在物理内存可能是非连续的,甚至与其他进程共享。
这样做的好处有内存的隔离和安全和资源的共享等。内存的隔离避免进程对其他进程或内核区域进行读写(安全)。而我们可以通过一个物理内存上的文件映射到多个进程虚拟内存空间中来实现资源的共享,实现物理页的零拷贝复用。之后,在内存阶段中,我们会对虚拟内存做详细的探讨。
因为进程使用的地址不是真实的物理内存上的地址,所以虚拟地址并不直接映射到物理内存的实际地址上,而是通过一个叫内存管理单元(MMU)的硬件进行地址转换。实际上,CPU使用的也是虚拟地址,要映射到物理内存上同样需要 MMU 的参与。
1.3.2.1 Different Mode, Different Space
上个阶段,我们谈论到了用户模式和内核模式,还简单地谈到了内核栈。为了实现系统的安全性和稳定性,我们将进程的虚拟内存空间划分为用户空间和内核空间。在32位机器上,由于处理器最多一次性处理的地址为32位的二进制数,只能访问
随着软件业的发展,软件占用的空间也越来越大。32 位的机器所能提供的 4GB 虚拟内存明显不够用。进而人们研发了新的 64 位计算机架构,解决了 32 位机器虚拟内存小的短板。 64 位机器的寻址的范围可比 32 位机器大得多了。 64 位机器下,高 16bits 用于区别用户空间和内核空间。只使用了低 48 位分别给进程的内核空间和用户空间进行编址。64 位进程虚拟内存布局如下:
Start End Size Use
0x0000000000000000 0x0000ffffffffffff 256TB user
0xffff000000000000 0xffffffffffffffff 256TB kernel
由上图,user space 的空间和 kernel space 两个地址空间各有 256TB,合在一起才是一个完整的进程虚拟地址空间。64bits 地址的高16bits,即 0xffff 代表内核空间,0x0000 代表用户空间。
1.3.2.2 User Space
进程的用户空间是每个进程所独有的,用于存储进程运行所需的代码、数据、堆和栈等。应用程序是可见的只有用户空间的地址,应用程序在此范围内执行其代码和处理数据。运行在用户模式下的程序不能直接访问内核空间资源,这增强了系统的安全性。
1.3.2.3 Kernel Space
内核空间是系统中所有进程共享的空间,用于运行操作系统的内核代码和处理核心任务,如设备管理、内存管理、进程调度等。内核空间对用户模式下的程序是不可见的,只能由运行在内核模式的操作系统代码访问。这部分通常保留较高的地址范围。
虽然内核空间在每个进程的地址空间中都是可见的,但普通用户程序不能直接读写或执行内核空间的代码或数据。当用户程序需要进行系统调用以请求操作系统的服务时,它将通过定义好的接口(如系统调用)切换到内核模式,此时才能执行内核代码。
1.3.3 Process Memory Layout
进程虚拟内存空间布局是指进程在虚拟内存中的组织和分配方式。它决定了一个进程的各种内存区域如何在虚拟地址空间中排列。典型的进程内存布局主要包括以下几个主要部分:
- 文本段(Text Segment):程序的二进制执行代码(r/x)。
- 数据段(Data Segment):初始化为非 0 过的全局变量和静态变量(r/w)。
- BSS段(Block Started by Symbol):存放初始化为 0 / 未初始化的全局和静态变量(r/w)。
- 只读数据段(Read-Only Data Segment):存储着不可修改的数据字符串常量(r)。
- 堆(Heap):用于动态内存分配(使用malloc)。在BSS段后开始,向上增长。
- 栈(Stack):用于存储函数调用的返回地址、局部变量和参数。位于高地址,向下增长。
- 环境变量(Environment Variables):存储与进程相关的环境信息,如路径、用户信息等。
- 命令行参数(Command Line Arguments):存储进程启动时传递的参数。
- 内核空间(Kernel Space):包含操作系统内核和相关数据结构,用户进程不可见。
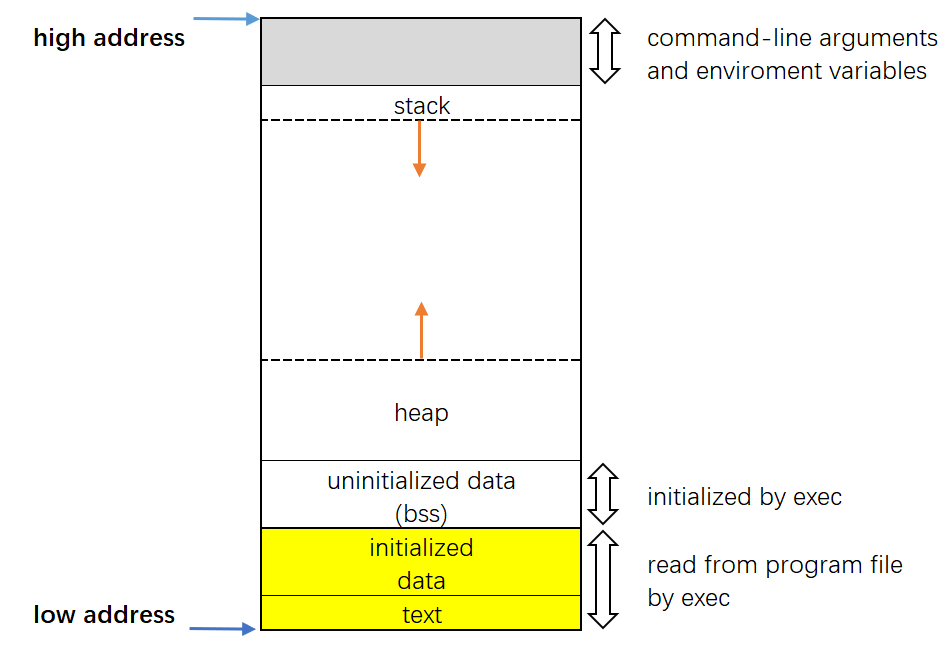
1.3.3.1 Get Your Hands On
这小节,我们通过运行自己的测试程序来观察以下某些变量在进程内存布局的哪部分。我们用到的测试程序如下:
#include <stdlib.h>
int global_b; //Uninitialized global variable
int main(){
static int static_c = 10;//static variable initializing
char* local_d = "hi,world";
void* p = malloc(100);
static_c ++;
free(p);
return 0;
}
为了保留更多的调试信息,在编译链接时加上-g参数,然后用gdb命令对可执行文件进行调试。需要到用到的gdb命令有:
list命令打印代码break main设置在 main 数处的断点。run开始执行程序,直到达到断点。info proc mappings显示进程的内存映射,包括各个内存段的地址范围info locals 显示当前函数的局部变量。print&local_d 打印局部变量 local_d 的地址。
我们得到的进程内存布局如下:
Mapped address spaces:
Start Addr End Addr Size Offset Perms objfile
0x555555554000 0x555555555000 0x1000 0x0 r--p hiprocess
0x555555555000 0x555555556000 0x1000 0x1000 r-xp hiprocess .text
0x555555556000 0x555555557000 0x1000 0x2000 r--p hiprocess .rodata
0x555555557000 0x555555558000 0x1000 0x2000 r--p hiprocess .rodata
0x555555558000 0x555555559000 0x1000 0x3000 rw-p hiprocess .data & bss
0x555555559000 0x55555557a000 0x21000 0x0 rw-p [heap]
0x7ffff7c00000 0x7ffff7c28000 0x28000 0x0 r--p libc.so.6
0x7ffff7c28000 0x7ffff7dbd000 0x195000 0x28000 r-xp libc.so.6
0x7ffff7dbd000 0x7ffff7e15000 0x58000 0x1bd000 r--p libc.so.6
0x7ffff7e15000 0x7ffff7e16000 0x1000 0x215000 ---p libc.so.6
0x7ffff7e16000 0x7ffff7e1a000 0x4000 0x215000 r--p libc.so.6
0x7ffff7e1a000 0x7ffff7e1c000 0x2000 0x219000 rw-p libc.so.6
0x7ffff7e1c000 0x7ffff7e29000 0xd000 0x0 rw-p
0x7ffff7fa9000 0x7ffff7fac000 0x3000 0x0 rw-p
0x7ffff7fbb000 0x7ffff7fbd000 0x2000 0x0 rw-p
0x7ffff7fbd000 0x7ffff7fc1000 0x4000 0x0 r--p [vvar]
0x7ffff7fc1000 0x7ffff7fc3000 0x2000 0x0 r-xp [vdso]
0x7ffff7fc3000 0x7ffff7fc5000 0x2000 0x0 r--p ld-linux-x86-64.so.2
0x7ffff7fc5000 0x7ffff7fef000 0x2a000 0x2000 r-xp ld-linux-x86-64.so.2
0x7ffff7fef000 0x7ffff7ffa000 0xb000 0x2c000 r--p ld-linux-x86-64.so.2
0x7ffff7ffb000 0x7ffff7ffd000 0x2000 0x37000 r--p ld-linux-x86-64.so.2
0x7ffff7ffd000 0x7ffff7fff000 0x2000 0x39000 rw-p ld-linux-x86-64.so.2
0x7ffffffde000 0x7ffffffff000 0x21000 0x0 rw-p [stack]
0xffffffffff600000 0xffffffffff601000 0x1000 0x0 --xp [vsyscall]
- 对照ELF进程内存布局的表,global_b全局变量和static_c静态变量的地址都位于data和bss段;
- char* local_d = "hi,world" 创建了一个指向字符串的指针变量,其中,字符串中的数据是read-only。因此,指针变量指向的数据位于rodata段。
- p指针和local_d的地址位于stack段,因为它们是个局部变量。
- p指针指向malloc函数动态内存分配的100个字节,其分配的内存位于heap段。
(gdb) print &static_c
$1 = (int *) 0x555555558010 <static_c>
(gdb) print &local_d
$2 = (char **) 0x7fffffffdee0
(gdb) print &global_b
$3 = (int *) 0x555555558018 <global_b>
(gdb) print &p
$4 = (void **) 0x7fffffffdee8
(gdb) print p
$5 = (void *) 0x5555555592a0
(gdb) print local_d
$6 = 0x555555556004 "hi,world"
1.4 Stack Spaces
对于进程来说,栈空间非常重要。我们知道局部变量的概念,但局部变量中的局部体现在哪里?对于学过高级语言的我们来说,在花括号“{ }”里面定义的变量就是局部变量了。这样理解当然没有问题,但是为什么会这样呢?
1.4.1 Stack Frame
当一个函数被调用时,系统会为该函数在栈空间上分配一个栈帧(stack frame),其中包含着所谓的局部变量、参数、返回地址和其他信息。栈是一个动态的概念,局部变量会随着栈帧的创建而被分配,当函数执行完毕、栈帧销毁时,这些局部变量也随之消失。
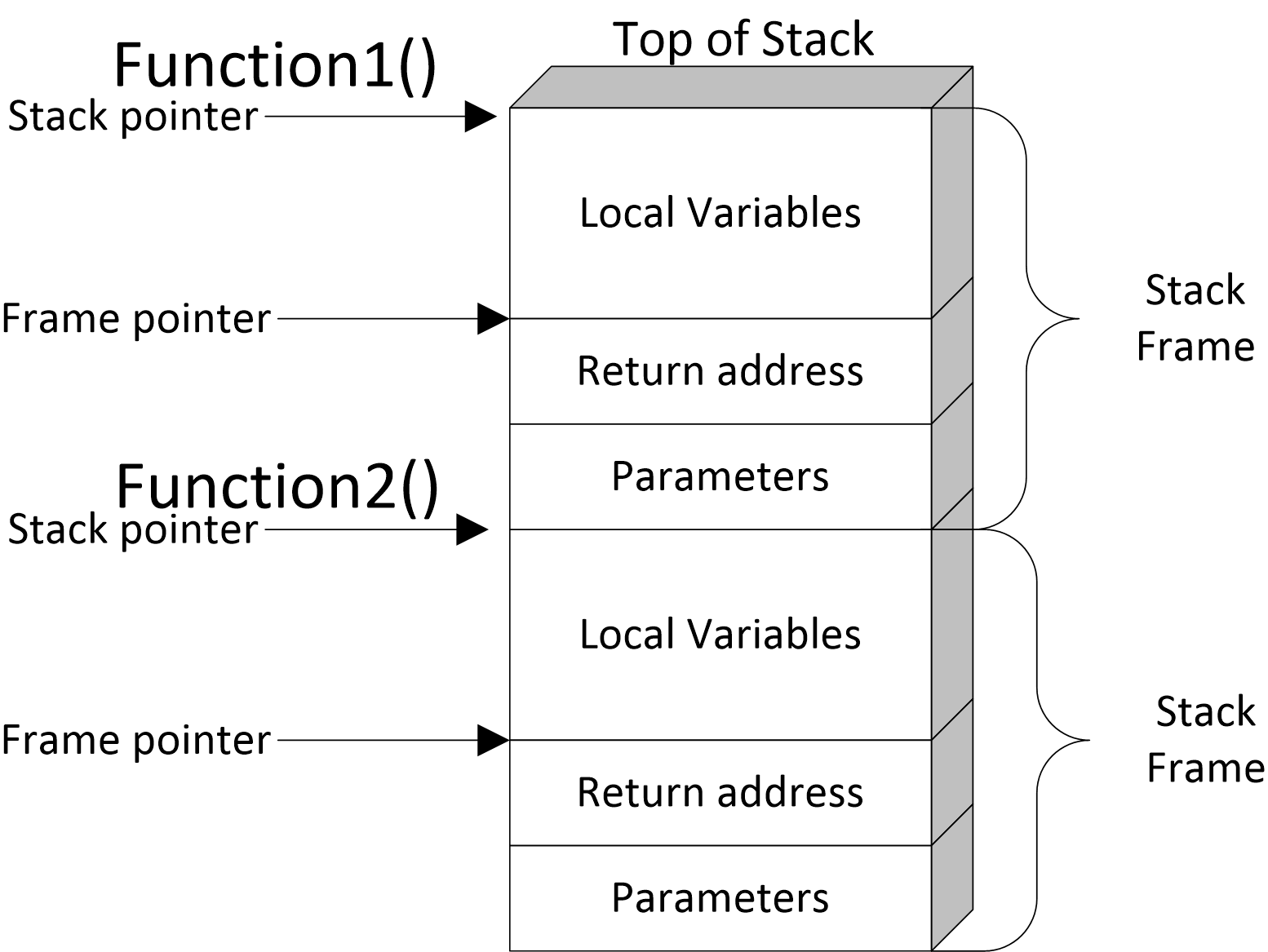
这也为我们使用堆空间带来一些警示。堆内存的申请通常是在函数内进行的,当栈帧销毁时,记录堆内存的指针也将不复存在。如果你没有使用语言提供的自动内存释放工具,你就必须在栈帧销毁前释放内存。当然,也可以像接力比赛一样,将指针的地址传给下一个函数。
1.4.2 Inspect the Stack Space
要查看进程的栈空间,我们还需要用到的 GNU Debugger ,在这次 DIY 的实验中,我们会用到下面的实验代码:
#include <stdio.h>
int global_g = 5;
int hello(){
int local_h = 10;
printf("hello\n");//breakpoint
return 0;
}
void world(){
}
int main(){
int local_i = 0;
hello();
world();
return 0;//breakpoint
}
我们会用到相关的gdb命令如下:
info frame:指令的缩写形式为i f,查看函数调用帧所有信息。info registers:查看寄存器的情况(除了浮点寄存器)。info register rbp:查看栈基地址寄存器值。(Base Pointer) | r 表示机器是64位info register rsp:查看栈顶地址寄存器值。(Stack Pointer)x/10x $sp:查看sp(stack pointer,栈顶)开始10个单位的数据(16进制),每个单位是一个字(在64位机器中是8字节)next:n,步进step overstep:s,步入step indisas/disass/disassemble:反汇编指令。有许多选项,如/m,/r。
我们用gdb查看变量的地址:
(gdb) print &local_h
$5 = (int *) 0x7fffffffde0c
(gdb) info frame
Stack level 0, frame at 0x7fffffffde20:
rip = 0x55555555515c in hello (stack.c:5); saved rip = 0x7fffffffde2f
called by frame at 0x7fffffffde28
source language c.
Arglist at 0x7fffffffde10, args:
Locals at 0x7fffffffde10, Previous frame's sp is 0x7fffffffde20
Saved registers:
rbp at 0x7fffffffde10, rip at 0x7fffffffde18
(gdb) print &local_i
$6 = (int *) 0x7fffffffdedc
(gdb) i f
Stack level 0, frame at 0x7fffffffdef0:
rip = 0x5555555551a4 in main (stack.c:17); saved rip = 0x7ffff7c29d90
source language c.
Arglist at 0x7fffffffdee0, args:
Locals at 0x7fffffffdee0, Previous frame's sp is 0x7fffffffdef0
Saved registers:
rbp at 0x7fffffffdee0, rip at 0x7fffffffdee8
1.4.3 Stack Frame Information
每当一个函数被调用时,都会创建一个全新的栈帧。和系统调用/中断等一样,我们需要在栈帧销毁时回到原函数的下一条指令继续执行。这就需要保存类似的一系列的上下文信息。其中,一部分信息由调用函数(Caller)保存,另一部分信息由被调用函数(Callee)保存。
int add(int x, int y){
return x + y;
}
int main(){
int a = 32;
int b = 64;
int sum = add(a, b); // <-- line 7
}
函数调用发生在第七行。调用函数会先将参数 b 和 a 的值压栈。然后将下一条指令的返回地址给压栈。之后,调用函数还需要保存部分寄存器(可能被被调函数修改的易失寄存器,比如 EAX, ECX, EDX 等)。被调用函数会保存使用频率相对低的寄存器(EBX, EDI, ESI 等),另外还会将函数里的局部变量压栈。
第二课 Process States and Process Switching
2.1 Process States
一个进程的生命周期从创建(new) 个进程到进程的 终止(terminated),一般会经历五种不同的状态:
- 新建态(New)
- 就绪态(Ready)
- 运行态(Running)
- 等待态(Waiting)
- 终止态(Terminated)
2.1.1 New
当一个新的进程被创建时,该进程会首先进入新建态(new),这是进程生命周期中的一个瞬间过程。在这个瞬间的状态中,操作系统会为进程创建一个PCB,初始化PCB和进程的状态,随后将指令指针指向指令入口地址。之后,进程会等待操作系统的许可,以进入就绪态(ready) 队列。
- 在桌面操作系统中,进程通常会被自动批准进入就绪态。
- RTOS中,为避免系统资源饱和,可能会对进程的准入进行延迟处理,以满足进程的时限要求。
每个新进程的创建都会有一个父进程。一般情况下,引起进程创建的主要有三类事件:
(1)系统启动;
(2)用户请求(exec()系统调用);
(3)其他进程复制(fork()系统调用)。
2.1.1.1 Newborn Processes in System Booting
在5. System Boots Up的最后,我们简单了解了一下Linux这种类Unix系统是如何启动的。我们看到,在系统启动时,有些进程在“明处”,而有些进程在“暗处”。我们所能看到的实际上都是用户可见的进程(user-visible process),而还有很多进程是我们看不到的,它们时刻支持着系统的运行。对于这类进程,我们称之为守护进程(Daemon)。
2.1.1.2 fork()
进程fork()出来的进程是指一个正在运行的进程通过调用fork()系统调用来创建一个新的子进程。这个子进程是父进程的副本,拥有相同的代码和数据,但在操作系统中作为一个独立的进程运行。
#include <unistd.h>
pid_t fork();
/*
Parameters: None.
Return value:
- On success: Returns the process ID (PID) of the child process to the parent process, and 0 to the child process.
- On failure: Returns -1 and sets errno appropriately.
*/
通过不同的返回值,我们可以区分父子进程并执行不同的branch逻辑代码。
2.1.1.3 You're the Master
用户请求创建的进程是指用户通过操作系统界面或命令行输入指令,要求系统启动某个应用程序或服务。例如,用户双击桌面上的图标或在命令行输入启动命令,这些操作都会触发进程的创建。下面是exec 系列函数的两个常见变体,用于替换子进程的地址空间,使其执行新的程序。
#include <unistd.h>
int execl(const char *path, const char *arg, ...);
/*
Parameters:
1. path: The path to the executable file.
2. arg: The argument list, terminated by a NULL pointer.
Return value:
- On success: Does not return, as the new program replaces the current process.
- On failure: Returns -1 and sets errno appropriately.
*/
int execv(const char *path, char *const argv[]);
/*
Parameters:
1. path: The path to the executable file.
2. argv: An array of argument strings, terminated by a NULL pointer.
Return value:
- On success: Does not return, as the new program replaces the current process.
- On failure: Returns -1 and sets errno appropriately.
*/
在这个过程中,每个进程都会有相应的父进程负责其创建过程。要启动某个应用程序时,会先使用fork系统调用来创建一个子进程,然后在子进程中使用exec系列系统调用(如execl、execv等)来加载并执行新的程序。
2.2 Terminated
当进程执行完毕或由于某种原因被终止,进程就会进入终止态(terminated)。在这个状态下,操作系统会回收该进程所占用的资源。同样,进程进入终止态也有几种不同的原因,比如:
(1)Normal exit (voluntary);
(2)Error exit (voluntary);
(3)Fatal error (involuntary);
(4)Killed by another process (involuntary)
进程终止后,操作系统会收集进程的一些信息(会计信息等)并移除进程的PCB。
2.2.1 Normal Exit ()
正常退出是指进程自愿完成其任务并退出。这通常发生在用户关闭应用程序或进程完成其预定任务时。例如用户关闭一个应用程序或编译器完成编译任务后退出。
#include <stdlib.h>
void exit(int status);
/*
Parameters:
1. status: The exit status of the process. Typically, 0 indicates success, and non-zero indicates failure.
Return value: No return.
*/
当参数 status = 0 时,代表正常退出。这时系统将会释放进程所有申请的相关资源,最后调用 _exit() 通知内核终止进程。
#include <unistd.h>
void _exit(int status);
/*
Parameters:
1. status: The exit status of the process. Typically, 0 indicates success, and non-zero indicates failure.
Return value: No return.
*/
2.2.2 Error Exit
错误退出是指进程遇到错误并自愿退出。例如,程序尝试访问无权限的目录时,可能会选择退出并返回错误代码。当遇到某种错误时,我们就会将 status 设置成一个非零值来调用 exit(status) 终止程序,参数数值表示了代码退出时的状态,以便后续的跟踪。
错误退出时,进程终止的流程和普通退出一样,只不过状态码不一样。
2.2.3 Fatal Error
致命错误是指进程遇到无法恢复的错误并被操作系统强制终止。例如,发生段错误或除零错误时,操作系统会强制终止进程。这时,操作系统会直接调用 _exit() 跳过 exit() 的资源清理流程。
2.2.4 Killed by Others
进程可能会被其他进程强制终止。这通常发生在用户通过任务管理器终止无响应的程序,或者父进程决定终止其子进程。
2.2.5 Process Return Code
和函数结束时返回值一样,当进程终止也会返回一个“码”,这是一个整数值。表示进程在终止时的状态。这个代码用于指示进程是否成功执行或是否发生了错误。
- 成功执行:进程成功完成其任务,通常会返回一个值
0。 - 错误发生:进程执行遇到错误,通常返回一个非零值。不同的值用于代表不同类型的错误。
在Linux中,退出码的范围往往是 0-255,这些退出码可以帮操作系统或用户了解进程的执行结果。根据退出码采取相应的措施。
2.3 Process Switching
2.3.1 Five-State Model
我们说进程通常而言会有五种状态,其实我们提到的是进程的五态模型,包括新建态、就绪态、运行态、等待态和终止态。任何运行中的进程在生命周期中都可能经历这五种不同的状态。通过将进程划分为不同的状态,操作系统能够更方便的管理计算机资源,为进程分配所需要的资源。
2.3.1.1 State Switching in Five-State Model
在进程的五态模型中,除了我们之前介绍的新建态和终止态,进程往往还会出现就绪态、运行态和等待态(waiting)/阻塞态(blocked)/睡眠态(sleeping)。
当进程具备可执行的条件,进程就会进入就绪态。这时,进程会等待被调度器分配CPU时间片来执行。同一时间,可能会有多个进程同时处于就绪态,以一定的顺序等待CPU的调度。为了管理这些就绪进程,操作系统会将这些进程放到一个链表实现的队列中来管理。
一旦就绪态的进程获得CPU时间片,开始执行代码,那么它就进入了运行态。运行态的进程可能会由于各种各样的情况重新进入就绪态或者进入阻塞态。
如果进程需要等待某个事件(如I/O操作的完成、资源的可用等)因而无法继续进行,进程就会被阻塞而进入等待队列。当事件发生(I/O操作已经完成)了,阻塞的进程会被唤醒,重新进入就绪态。
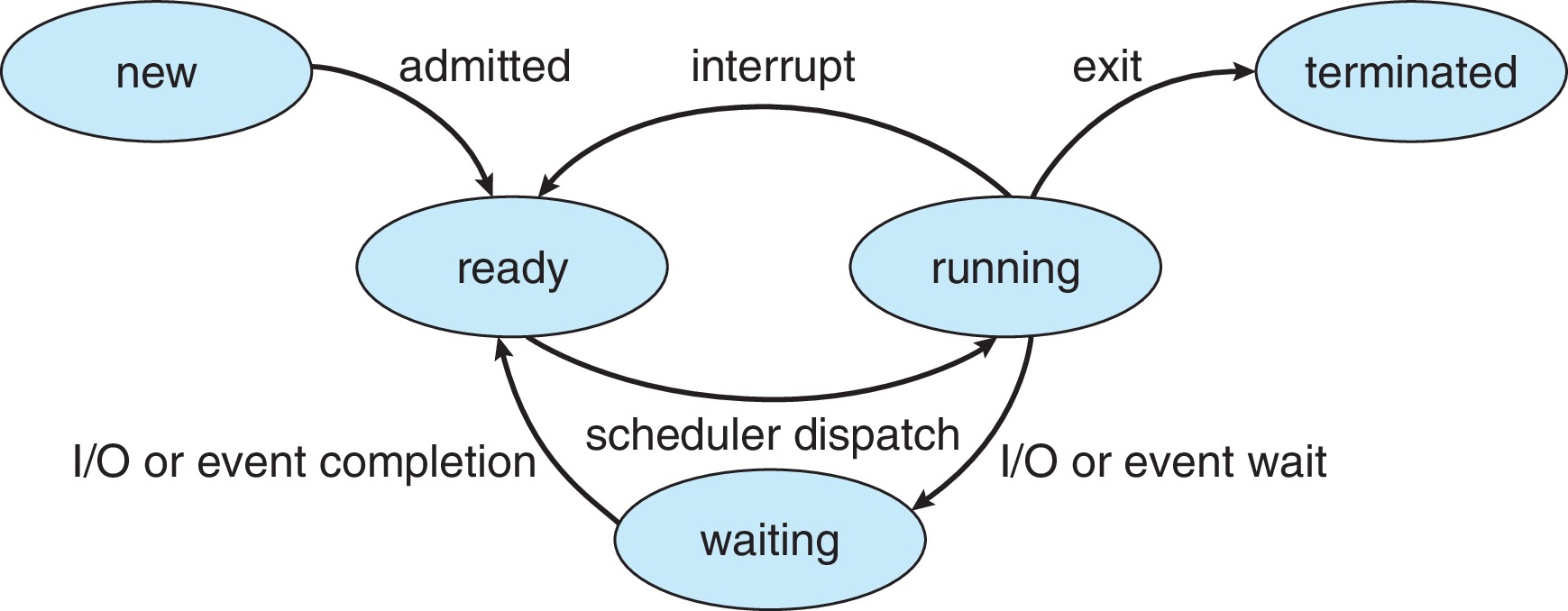
在五态模型下,进程的状态转变可能会出现以下情况:
- NULL -> New:新进程的创建。
- New -> Ready:当进程创建完成后,系统将其放入就绪队列,等待调度器的调度。
- Ready -> Running:操作系统的进程调度器选择就绪态进程,为其分配CPU资源。
- Ready -> Exit:在被调度之前进程就被其他进程终止(可能是父进程)。
- Running -> Ready:进程的时间片用完或由于其他调度策略导致进程失去CPU资源(被动)。
- Running -> Blocked:进程等待某个事件的发生而自愿放弃CPU资源。
- Running -> Exit:通常是进程正常退出,也可能是运行过程中发生错误或被终止。
- Blocked -> Ready:阻塞进程接收到事件完成的信号,进入就绪态等待操作系统调度。
2.3.1.2 Ready Queue and Wait Queue
为了方便管理,操作系统将不同状态的进程放入不同的队列当中进行管理,这个队列是链式的,方便进行PCB的插入和删除。以下是这些链式队列的大致结构。
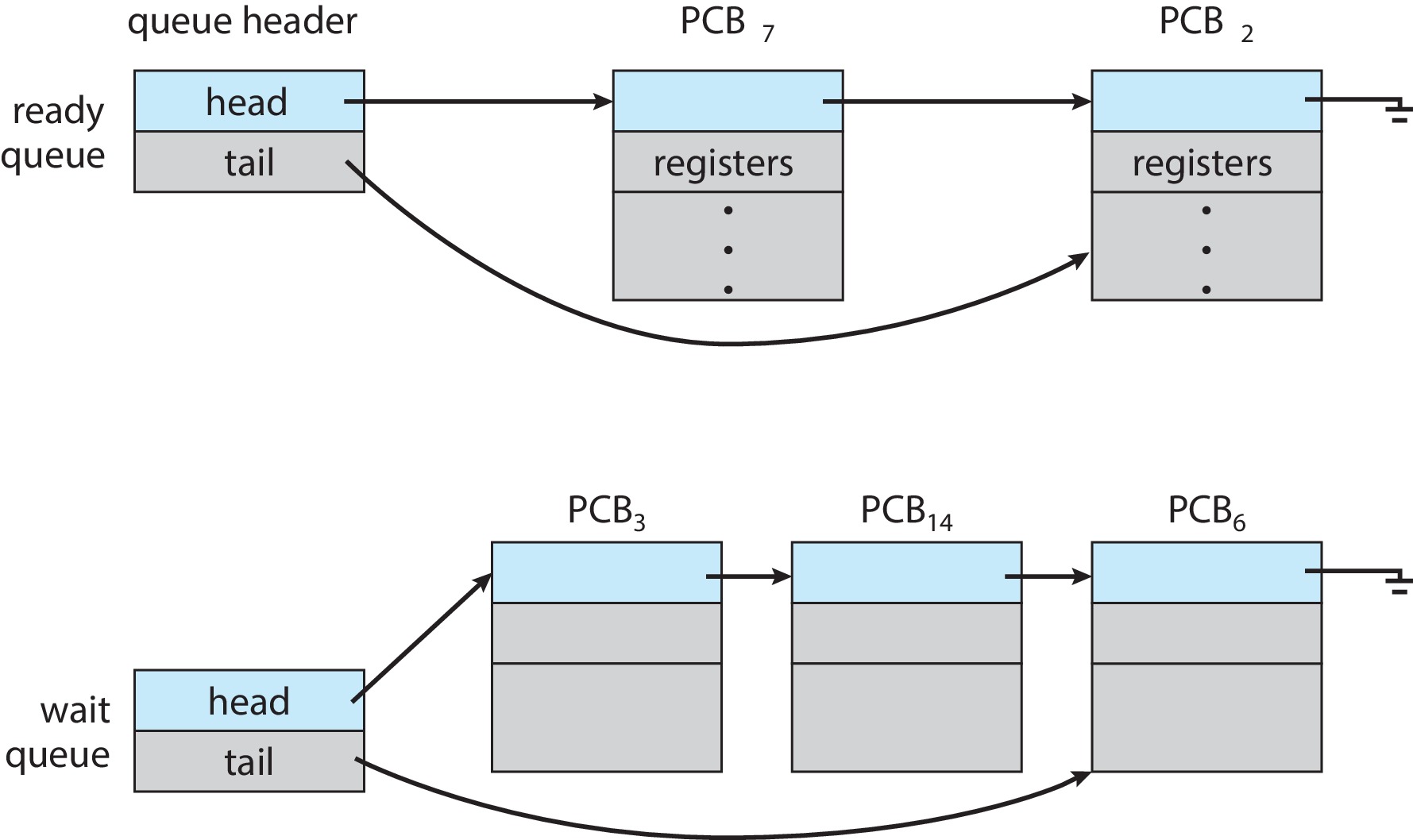
当进程被阻塞进入阻塞态时,操作系统会将阻塞的进程插入到阻塞队列中进行管理,根据不同原因的阻塞,阻塞队列可能有多个。
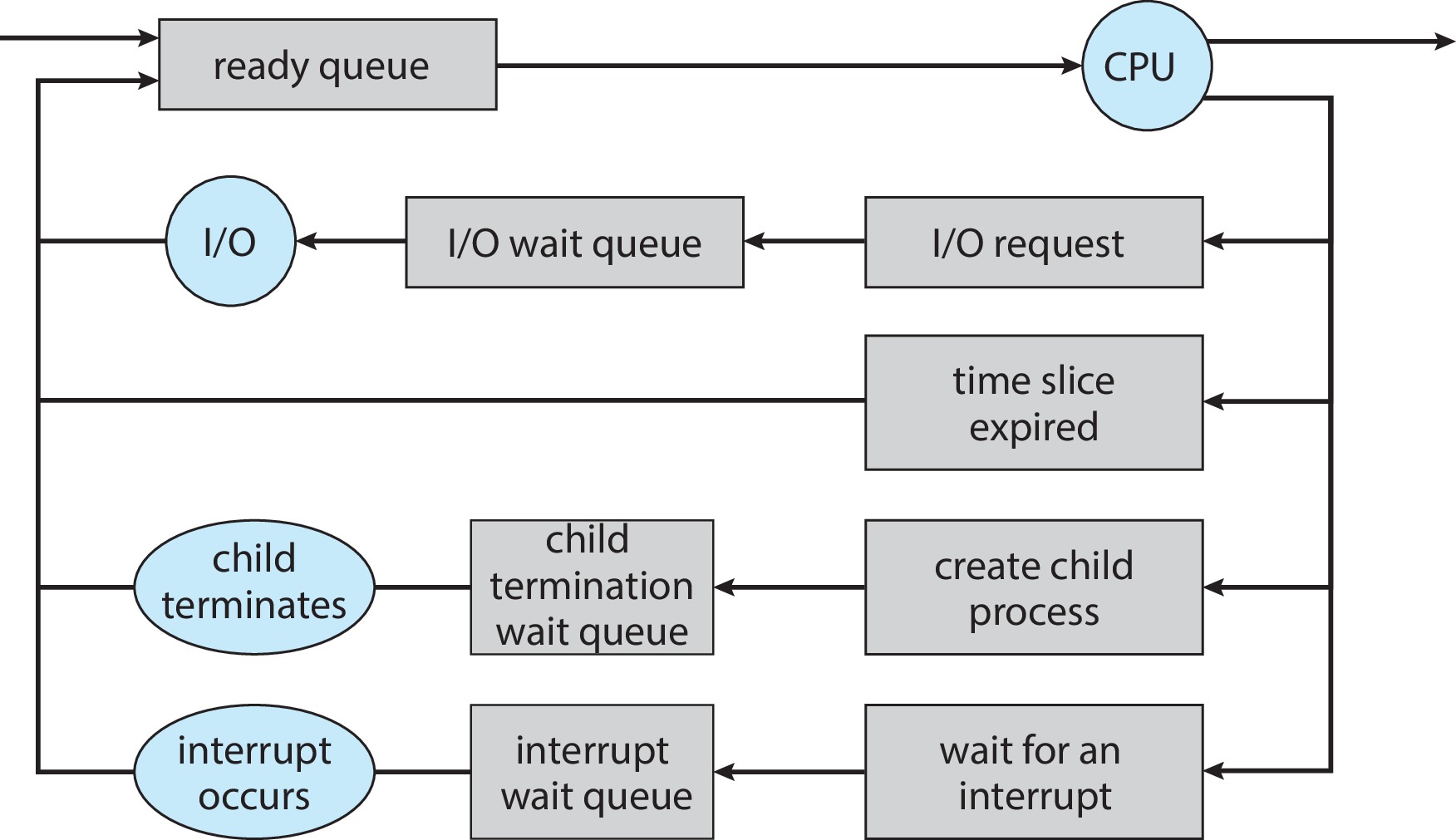
2.3.2 Seven-States Model
在五态模型中,我们的视角一直局限于主存。然而,当主存资源耗尽时,我们可以将一些暂时用不到的进程交换(swap)到二级存储器(外存)中,从而腾出更多的资源留给系统中的其他进程,同时也能在一定程度上避免死锁的发生。这就是为什么我们引入七态模型。
2.3.2.1 Swapping and Suspend
在引入七态模型后,我们增加了两个新的状态:Suspended Ready(就绪挂起) 和 Suspend Blocked (阻塞挂起)。这两个状态使得操作系统能够更高效地管理主存和外存资源。
当进程资源被交换到外存中时,我们就称进程被挂起了。在七态模型中,我们就引入了两种挂起态,即进程可以在就绪态被挂起(Suspended ready),也可以在阻塞态被挂起(Suspended blocked)。
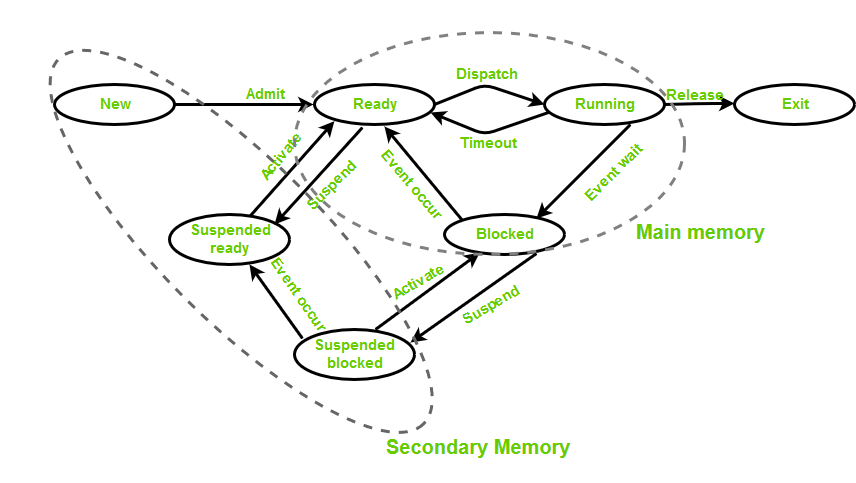
2.4 Context Switch
我们上面看到,进程有多种状态。而在计算机系统中,即使是单核 CPU,也会运行多个进程。为了提高 CPU 的利用率,人们通过优化调度器的调度策略来合理分配 CPU 资源。例如,当一个进程因 I/O 操作而进入阻塞状态时,调度器会将 CPU 切换到另一个就绪的进程上运行。
而为了保证阻塞进程在提交程序运行完毕后能够接着执行,调度器进行调度时就会进行进程上下文切换,保存被调度进程的上下文信息 ,加载调度进程的上下文信息。
2.4.1 CPU Scheduling
在之前学习中断时,我们介绍了中断上下文的保存。当时,我们所关心的进程生命周期为:进程创建 -> 使用一些系统调用 -> 进程结束。而且系统一时间只能运行一个进程,并不考虑程序的并发执行和进程阻塞等其他因素。因此,中断上下文往往很简单,只包含一些寄存器,因为系统调用结束后回到用户态继续执行时所需的上下文信息很少。
然而,CPU 从头到尾一次只完整地运行一个程序显然不可接受。这样不仅会导致用户体验变差,CPU 的利用率也可能很低。为了解决这种情况,人们提出了多道程序设计的理念,使得当一个进程等待I/O时,调度器会调度其他进程到 CPU 上运行。为了使系统更用户友好,我们可以让系统内的应用轮流地各执行 1ms,使用户感觉所有进程都在同时运行。这就是分时多任务系统的理念。
在之后的阶段中,我们会介绍很多CPU调度的相关策略。为了使CPU的利用率和系统响应速度更好,操作系统需要选择特定的调度策略对系统内的进程进行调度。CPU调度决定了在任意时间点,哪个进程应该获得CPU的使用权。只要CPU调度发生了,必然牵扯到不同进程的状态转换,只要状态转换了,系统就需要保存进程的上下文信息。
2.4.2 Process Contexts
我们之前提到了,任何对进程的操作最终都会反映在PCB的修改上。当一个进程由于某些原因从运行态上转换成其他状态时,为了保证进程在被暂停后能够恢复并正确继续执行,我们需要保存进程内部(PCB)的一些状态信息。这个信息就是进程上下文。进程上下文通常包括:
- CPU寄存器的状态:这包括通用寄存器(如AX,BX,CX等)、程序计数器PC、堆栈指针BP,SP、指令寄存器IBR、状态寄存器(如EFLAGS)等。
- 进程的内存状态:这包括代码本身(CS)、相关的数据、堆栈以及文件描述符等资源。
- 进程的特定控制信息:如进程ID、进程的优先级、进程的账户信息、进程的调度状态等。
进程切换时状态时,硬件会自动保存一些上下文(PC寄存器),操作系统会保存剩下的上下文。
2.4.3 Context Switch
当OS需要调度一个进程切换到另一个进程时,它会保存进程的上下文,并恢复下一个要运行进程的上下文。这个保存和恢复的过程被称为上下文切换。

2.4.3.1 Switching Costs
进程切换开销是上下文切换中所耗费的系统开销,如上图进程P1执行前后的空闲时间段,这段空闲时间段完全被进程切换所占用。在分时系统中,进程的切换开销往往是调度器选择时间片长度的重要考量因素。使得CPU在处理进程间切换的时间占整个CPU运行时间的比重在一个合理的范围上。
2.4.3.2 Switching Triggers
一般情况下,导致进程上下文切换的情况有以下三种:
- Interrupts
- Multitasking
- User/Kernel switch
Interrupts: 中断是硬件或软件发出的信号,表明需要处理器立即注意的事件。当CPU接收到中断信号时会暂停当前执行的进程(或线程),保存其状态,并切换到一个专门的中断处理程序来响应和处理这个事件。处理完中断后,操作系统可以选择:
- 恢复被中断的进程的执行。(系统调用这类简单的中断可以只保存中断上下文)
- 切换到另一个进程,特别是在中断处理期间如果有更高优先级的进程变为就绪状态的情况。
Multitasking: 多任务处理是操作系统为了更高效地利用处理器资源而进行的进程调度。操作系统会根据特定的调度策略,决定何时将正在运行的进程切换出处理器,以及何时让新的进程或线程占用处理器资源。上下文切换的需求通常来源于以下两种情形:主动和被动,这部分将在进程的状态及转换部分解释。
Kernel/User Switch: This trigger is used when the OS needed to switch between the user mode and kernel mode.When switching between user mode and kernel/user mode is necessary, operating systems use the kernel/user switch.
2.5 Moving Beyond: Making New Processes
本节课的开始,我们说引起进程创建的主要有系统启动、用户请求和其他进程复制的三类事件。那实际情况如何,n个进程是如何变到n+1个进程的?这些就是我们本小节拓展所要解释的,同时更详细地探索这些系统调用实际上都做了什么。
2.5.1 Fork and Execute
在5. System Boots Up中,我们最后简单地提了一嘴,在Linux中,进程号为1的进程是所有进程的祖先进程,init(或systemd)进程是系统启动时由内核创建的第一个进程。之后它会作为父进程启动一些守护进程和用户进程。然后再由这些用户进程生成自己的子进程,这些过程就是通过fork()系统调用完成的。
2.5.1.1 Copy-On-Write Sharing
在前面,我们查看了fork()系统调用和exec()系列系统调用的一些函数原型。当父进程用fork()系统调用生成子进程时,一个虚拟内存映像完全一样的子进程就会被创建出来。fork()函数很特别,它有两个返回值,用于区分父子进程。我们可以用不同的返回值来执行不同的逻辑。

虽然我们说子进程的内存空间是父进程的拷贝,但是实际上操作系统并不会真的原封不动地复制整个进程内存空间。这时因为操作系统用到了写时复制的技术,我们在内存管理的章节中会学到。
2.5.1.2 New Process with New Program
子进程创建好了之后,我们可以继续使用父进程的代码逻辑。但大多数时候,我们都想让子进程执行其他的程序,这时候就会用exec()系列的系统调用把当前的进程内存空间进行替换。下面的两个程序就展示了这两种截然不同的子进程执行逻辑。
// fork.c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main(){
int ret = fork();
if(ret == 0){
printf("This is child process.\n");
}
else{
printf("This is parent process.\n");
wait(NULL);
}
return 0;
}
// fork.c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
int ret = fork();
if (ret == 0) {
char *args[] = { NULL };
execv("./hello", args);
} else {
wait(NULL);
}
return 0;
}
上面的例子中,我们用 fork() 和 execv() 系统调用来创建一个子进程,并在子进程中执行一个新的程序。在子进程中,使用 execv() 系统调用执行新的程序 ./hello。execv() 替换当前进程的地址空间,使其执行新的程序。而在父进程中,我们调用wait()系统调用,等待子进程结束,避免出现僵尸进程。
当我们使用strace -f ./fork时,我们会看到程序实际上用到了两个execve()和一个clone()系统调用。第一个execve()用于将当前进程替换为 ./fork 程序;接下来,通过 clone() 实现父进程内存空间的复制(fork() 库函数实际上是对 clone() 系统调用的封装);在子进程中,execv 系统调用被用来执行新的程序 ./hello。
execve("./fork", ["./fork"], 0x7ffeae4313f8 /* 55 vars */) = 0
...
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLDstrace: Process 20909 attached
, child_tidptr=0x72b7e9c79a10) = 20909
...
[pid 20909] execve("./hello", [], 0x7fffaaac2478 /* 55 vars */) = 0
...
[pid 20909] exit_group(0) = ?
[pid 20909] +++ exited with 0 +++
<... wait4 resumed>NULL, 0, NULL) = 20909
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=20909, si_uid=1000, si_status=0, si_utime=0, si_stime=0} ---
exit_group(0) = ?
+++ exited with 0 +++
在第二种执行逻辑中,其实有一步有些许的多余。我们先是克隆父进程的内存映像,接着对其进行替换。那我们为什么不在最开始的时候就创建一个新的子进程,避免不必要的内存复制操作。而且 Linux 并不保证fork()之后父/子进程执行的先后性。
2.5.2 POSIX Spawn
posix_spawn 提供了一个更高级的接口,简化了进程创建和执行的过程。posix_spawn 使用 clone3 系统调用来创建一个新的子进程。与 fork 不同,posix_spawn 不会复制父进程的内存空间,而是直接创建一个新的进程,并立即执行指定的程序。它的函数原型如下:
#include <spawn.h>
int posix_spawn(pid_t *restrict pid, const char *restrict path,
const posix_spawn_file_actions_t *file_actions,
const posix_spawnattr_t *restrict attrp,
char *const argv[restrict],
char *const envp[restrict]);
/*
Parameters:
1. pid: A pointer to a variable where the process ID of the child process will be stored.
2. path: The path to the program to be executed.
3. file_actions: A pointer to a posix_spawn_file_actions_t structure that specifies file actions to be performed in the child process before executing the program. Can be NULL.
4. attrp: A pointer to a posix_spawnattr_t structure that specifies attributes for the child process. Can be NULL.
5. argv: An array of argument strings passed to the new program. The array must be terminated by a NULL pointer.
6. envp: An array of environment strings passed to the new program. The array must be terminated by a NULL pointer.
Return value:
- On success: Returns 0 and stores the process ID of the child process in the variable pointed to by pid.
- On failure: Returns an error number (positive integer) and sets errno appropriately.
*/
2.5.2.1 Fork vs. Spawn
测试代码如下,这段代码和我们前面fork.c的作用相同:
// spawn.c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <spawn.h>
#include <stdlib.h>
extern char **environ;
int main() {
pid_t pid;
char *args[] = { "./hello", NULL };
int status = posix_spawn(&pid, "./hello", NULL, NULL, args, environ);
if (status == 0) {
printf("Child process created with PID: %d\n", pid);
waitpid(pid, NULL, 0);
} else {
perror("posix_spawn failed: ");
}
return 0;
}
2.5.2.2 What Spawn Brings?
我们不再这里示例strace -f ./spawn了,我们想一想相比于fork(),posix_spawn()带给我们哪些好处。看看上面的代码,你可能已经发现一个最直接的好处,即posix_spawn 将进程创建和程序执行结合在一个调用中,简化了代码逻辑,减少了开发者犯错的可能。
通过 posix_spawn_file_actions_t 和 posix_spawnattr_t 结构体,可以在创建新进程时指定文件操作和进程属性,减少了额外的系统调用。
此外,在使用posix_spawn()时,使用的clone()系统调用实际上会有CLONE_VM和CLONE_VFORK这两个字段。CLONE_VM表示子进程将与父进程共享同一个内存空间,但是不会共享内核资源(文件描述符、信号处理);CLONE_VFORK表示在子进程调用execve()或_exit()之前,父进程会被挂起。
2.5.3 Clone Syscall
我们在上面看到,fork()和posix_spawn()都用到了不同类型的clone()来生成一个子进程。clone()为我们提供了细粒度的操作,我们可以用clone()完成很多有趣的操作。甚至上线程都是用类似的clone3()系统调用完成的。clone()的函数原型如下:
#include <sched.h>
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg, ...);
/*
Parameters:
1. fn: A pointer to the function to be executed by the child process. This function takes a single argument of type void* and returns an int.
2. child_stack: A pointer to the stack space for the child process. The stack grows downwards, so this should point to the end of the allocated stack space.
3. flags: A bitmask of flags that control the behavior of the child process. Common flags include:
- CLONE_VM
- CLONE_FS
- CLONE_FILES
- CLONE_SIGHAND
- CLONE_PARENT
- CLONE_THREAD
- CLONE_VFORK
4. arg: A pointer to the argument to be passed to the function fn.
Return value:
- On success: Returns the process ID (PID) of the child process.
- On failure: Returns -1 and sets errno appropriately.
*/
2.5.3.1 Clone3 Syscall
clone3()是clone()的改进,相比于后者,clone3()有许多优势,如:更灵活的参数传递、可扩展性更佳等。clone3()的函数原型如下:
#include <sched.h>
int clone3(struct clone_args *cl_args, size_t size);
/*
Parameters:
1. cl_args: A pointer to a struct clone_args, which contains various fields to specify the behavior and properties of the child process.
2. size: The size of the struct clone_args structure.
Return value:
- On success: Returns the process ID (PID) of the child process.
- On failure: Returns -1 and sets errno appropriately.
*/
struct clone_args {
uint64_t flags;
int64_t pidfd;
uint64_t child_tid;
uint64_t parent_tid;
uint64_t exit_signal;
uint64_t stack;
uint64_t stack_size;
uint64_t tls;
uint64_t set_tid;
uint64_t set_tid_size;
uint64_t cgroup;
};
/* struct clone_args fields:
- flags: A bitmask of flags that control the behavior of the child process. Common flags include CLONE_VM, CLONE_FS, CLONE_FILES, CLONE_SIGHAND, CLONE_PARENT, CLONE_THREAD, CLONE_VFORK, CLONE_SYSVSEM, CLONE_SETTLS, CLONE_PARENT_SETTID, and CLONE_CHILD_CLEARTID.
- pidfd: A file descriptor that refers to the PID of the child process.
- child_tid: A pointer to a location where the child process's thread ID will be stored.
- parent_tid: A pointer to a location where the parent process's thread ID will be stored.
- exit_signal: The signal to be sent to the parent when the child exits.
- stack: A pointer to the stack space for the child process.
- stack_size: The size of the stack space.
- tls: A pointer to the thread-local storage (TLS) area.
- set_tid: A pointer to an array of TIDs to be set in the child.
- set_tid_size: The number of TIDs in the set_tid array.
- cgroup: A file descriptor referring to the cgroup to which the child process should be added.
*/
2.5.3.2 Clone Attributes
clone()和clone3()拥有基本相同的flags,用这些不同的flags,我们就可以完成各种各样有趣的事情。常见的flags和相关的释义如下:
/* Common flags:
- CLONE_VM: The child process shares the same memory space as the parent process.
- CLONE_FS: The child process shares the same file system information as the parent process.
- CLONE_FILES: The child process shares the same file descriptors as the parent process.
- CLONE_SIGHAND: The child process shares the same signal handlers as the parent process.
- CLONE_PARENT: The child process has the same parent process as the calling process.
- CLONE_THREAD: The child process is placed in the same thread group as the calling process.
- CLONE_VFORK: The parent process is suspended until the child process calls execve() or _exit().
- CLONE_SYSVSEM: The child process shares System V semaphore adjustments with the parent process.
- CLONE_SETTLS: The child process uses the TLS (Thread-Local Storage) area specified in the tls field.
- CLONE_PARENT_SETTID: The child's TID is set in the parent_tid field in the parent process.
- CLONE_CHILD_SETTID: The child's TID is set in the child_tid field in the child process.
- CLONE_CHILD_CLEARTID: The child process's TID is cleared in the child_tid field when the child exits.
- CLONE_UNTRACED: The child process is not traced by the parent process.
*/
2.5.3.3 Here Comes the Clone Version
#define _GNU_SOURCE
#include <sched.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <linux/sched.h>
#include <sys/syscall.h>
struct clone_args {
uint64_t flags;
int64_t pidfd;
uint64_t child_tid;
uint64_t parent_tid;
uint64_t exit_signal;
uint64_t stack;
uint64_t stack_size;
uint64_t tls;
uint64_t set_tid;
uint64_t set_tid_size;
uint64_t cgroup;
};
extern char **environ;
int main() {
pid_t pid;
char *args[] = { "./hello", NULL };
struct clone_args cl_args = {
.flags = CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND | CLONE_PARENT_SETTID | CLONE_CHILD_CLEARTID,
.pidfd = 0,
.child_tid = 0,
.parent_tid = 0,
.exit_signal = SIGCHLD,
.stack = 0,
.stack_size = 0,
.tls = 0,
.set_tid = 0,
.set_tid_size = 0,
.cgroup = 0
};
pid = syscall(SYS_clone3, &cl_args, sizeof(cl_args));
if (pid == -1) {
perror("clone3 failed");
exit(EXIT_FAILURE);
}
if (pid == 0) {
// Child process
execve("./hello", args, environ);
perror("execve failed");
exit(EXIT_FAILURE);
} else {
// Parent process
printf("Child process created with PID: %d\n", pid);
waitpid(pid, NULL, 0);
}
return 0;
}
第三课 Process Organization
3.1 Process Organization
3.1.1 Windows
3.1.2 Linux Process Tree
在Linux下,所有的进程都是以树形结构组织起来的。所有的进程都有其父进程(除了根进程 init或 systemd)。在bash命令行下,你可以用pstree命令来查看这样的树形结构,以获得所有进程及其父子关系的信息。同时,用ps命令可以查看当前系统下进程的各种信息。

在命令行下,一条命令实际上是由当前的 bash 创建一个进程,后面的参数是传给这个进程的参数。比如 ps、gcc 等。而平时我们经常使用 ./hello 来执行程序,为什么 ps 这些命令行命令不需要 ./ 呢?这是因为这些命令的路径问题。
命令行中的 ps、gcc 等命令通常位于系统的 环境变量 PATH 指定的目录中,例如 /usr/bin、/bin 等。bash 会在 PATH 环境变量指定的目录中查找命令,所以直接输入命令名即可执行。
而 ./hello 表示在当前目录下查找并执行 hello 程序,./ 显式指定了当前目录。如果没有在 PATH 中包含当前目录,就需要使用 ./ 来运行当前目录中的程序。
3.2 Process Group and Session(Process Control)
3.2.1 Process Group
进程组是操作系统中用于管理和组织进程的一种机制。一个进程组由一个或多个进程组成,这些进程可以相互协作完成某些任务。进程组的主要目的是为了方便信号的发送和管理。当我们用shell执行命令时,进程组就会被创建。
sleep 100 # a proc group with only 1 process.
echo "Hello, World!" > temp.txt & cat temp.txt # a proc group with 2 processes.
在Linux和Unix系统中,每个进程都有一个进程组ID,并且有其组标识符PGID。进程组中的所有进程共享同一个PGID。通常而言,fork()父进程和子进程在一个进程组中,进程组的ID是组长的ID。我们可以通过getpgid(pid_t pid)来获取指定进程的进程组ID。
子进程除了加入父进程的进程组外,还可以创建或加入其他的进程组。我们通过setpgid(pid_t pid, pid_t pgid)来设置指定进程的进程组ID,如果pid参数为0,则使用调用者的进程id,如果pgid是0,则由pid指定的进程id作为进程组id。比如setpgid(0, 0);就表示创建一个当前进程为进程组长的进程组。
进程组的一个常见用途是信号处理。信号会被发生给进程组的全体成员。当用户在终端中按下Ctrl+C时,系统会向前台进程组发送一个中断信号(SIGINT),终止该进程组中的所有进程。此外,进程组还会由于作业控制,因为在shell中,一个进程组通常被看作为一个作业(job)。
例如,以下代码展示了如何创建一个新的进程组并将子进程加入该进程组:
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main() {
pid_t pid = fork();
if (pid == -1) {
// fork failed
perror("fork");
exit(EXIT_FAILURE);
} else if (pid == 0) {
// Child process
setpgid(0, 0); // Create a new process group with the child process as the leader
printf("Child process: PID = %d, PGID = %d\n", getpid(), getpgid(0));
// Child process code here
} else {
// Parent process
printf("Parent process: PID = %d, PGID = %d\n", getpid(), getpgid(0));
// Parent process code here
}
return 0;
}
在这个示例中,子进程通过setpgid(0, 0)创建了一个新的进程组,并将自己设置为该进程组的组长。父进程和子进程的进程组ID可以通过getpgid(0)获取。
3.2.1.0 PGID System Calls
#include <unistd.h>
#include <sys/types.h>
pid_t getpgid(pid_t pid);
/*
Parameters:
1. pid: Process ID of the target process. If pid is 0, getpgid() returns the PGID of the calling process.
Return value:
- On success, returns the PGID of the specified process.
- On failure, returns -1 and sets errno to indicate the error.
*/
int setpgid(pid_t pid, pid_t pgid);
/*
Parameters:
1. pid: Process ID of the target process. If pid is 0, setpgid() sets the PGID of the calling process.
2. pgid: Process Group ID to be assigned. If pgid is 0, the PGID is set to the PID of the process specified by pid.
Return value:
- On success, returns 0.
- On failure, returns -1 and sets errno to indicate the error.
*/
3.2.2 Session
几个进程组又可以组成一个会话。会话中的所有进程都拥有相同的会话ID,会话ID是session leader的进程组ID,保存在task_struct中的session成员中。一个会话中有一个前台进程组,剩下的都作为后台进程组存在。
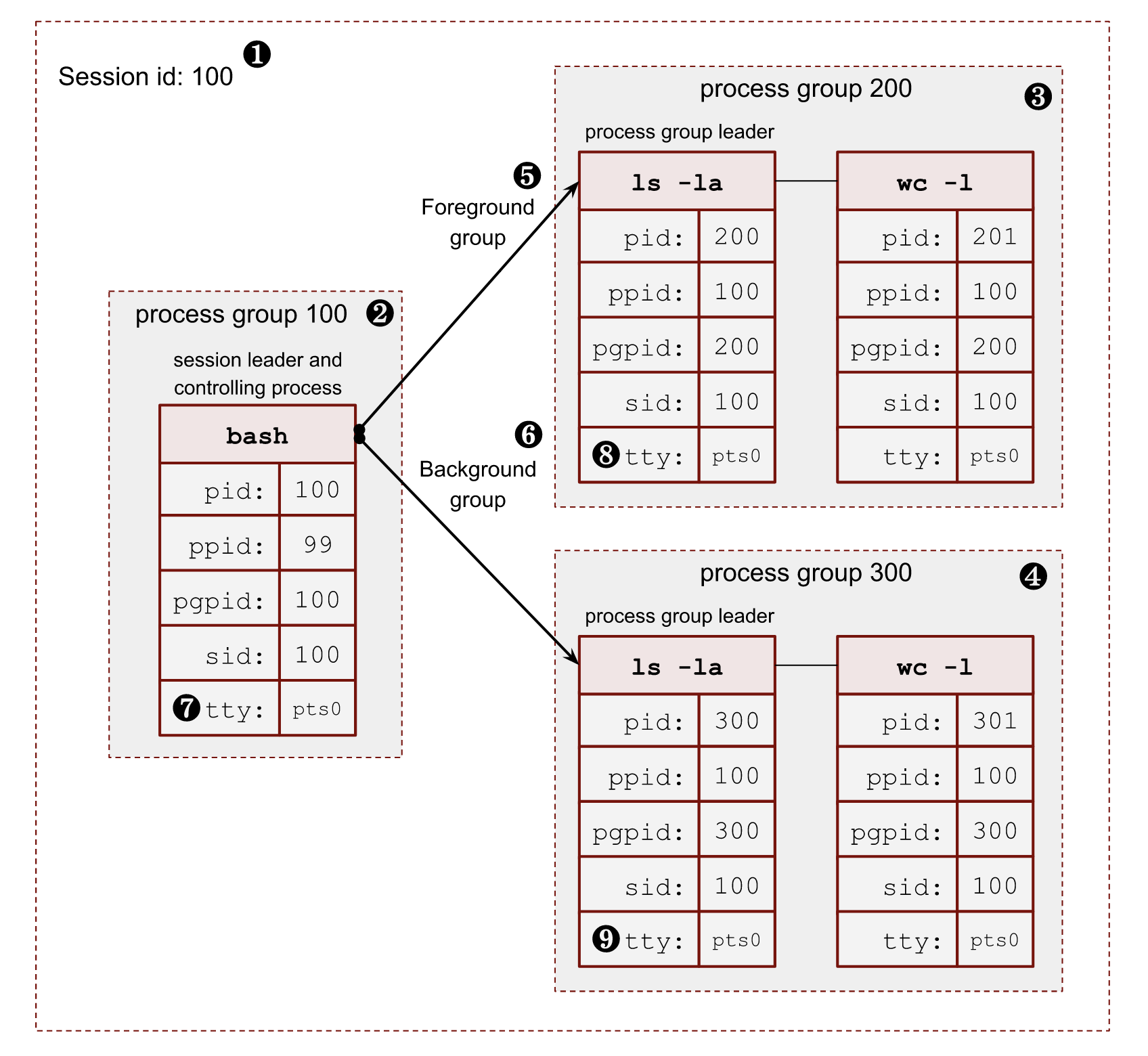
前台任务会阻塞当前会话,而后台任务不会阻塞当前会话。我们可以在shell命令后面加入&来将进程组作为后台任务运行。只有前台进程组中的进程可以读写终端,而后台进程组中的进程只能写终端,不能读终端。
sleep 5
# You cannot do anything before 5s passed.
sleep 5 & # background proc group
# You can do anything here.
此外,当你使用ctrl+C发生终止信号(下节课会了解到)时,信号只会发送给前台进程组的所有进程,而后台进程组中的进程不会受影响。
3.2.2.0 pgrp System Calls
#include <unistd.h>
#include <sys/types.h>
pid_t getpgrp(void);
/*
Parameters: None.
Return value:
- On success, returns the PGID of the calling process.
- On failure, returns -1 and sets errno to indicate the error.
*/
int setpgrp(void);
/*
Parameters: None.
Return value:
- On success, returns 0.
- On failure, returns -1 and sets errno to indicate the error.
*/
pid_t getsid(pid_t pid);
/*
Parameters:
1. pid: Process ID of the target process. If pid is 0, getsid() returns the SID of the calling process.
Return value:
- On success, returns the SID of the specified process.
- On failure, returns -1 and sets errno to indicate the error.
*/
pid_t setsid(void);
/*
Parameters: None.
Return value:
- On success, returns the SID of the calling process.
- On failure, returns -1 and sets errno to indicate the error.
*/
pid_t tcgetpgrp(int fd);
/*
Parameters:
1. fd: File descriptor of the terminal.
Return value:
- On success, returns the PGID of the foreground process group associated with the terminal.
- On failure, returns -1 and sets errno to indicate the error.
*/
int tcsetpgrp(int fd, pid_t pgrp);
/*
Parameters:
1. fd: File descriptor of the terminal.
2. pgrp: Process Group ID to be set as the foreground process group.
Return value:
- On success, returns 0.
- On failure, returns -1 and sets errno to indicate the error.
*/
pid_t tcgetsid(int fd);
/*
Parameters:
1. fd: File descriptor of the terminal.
Return value:
- On success, returns the SID of the session leader for the terminal.
- On failure, returns -1 and sets errno to indicate the error.
*/
3.2.3 Terminal
终端用于绑定一个会话,作为其控制台使用。
第四课 Orphans and Zombies
4.1 Orphan Process
如果父进程先于子进程结束终止,那么子进程就会变成孤儿进程。孤儿进程会被进程号为1的进程(init和systemd)接管,成为它们的子进程。孤儿进程并不会对系统造成直接的危害,操作系统会在孤儿进程运行完毕之后回收进程资源。但是,我们仍然有义务给孤儿进程一些关爱。
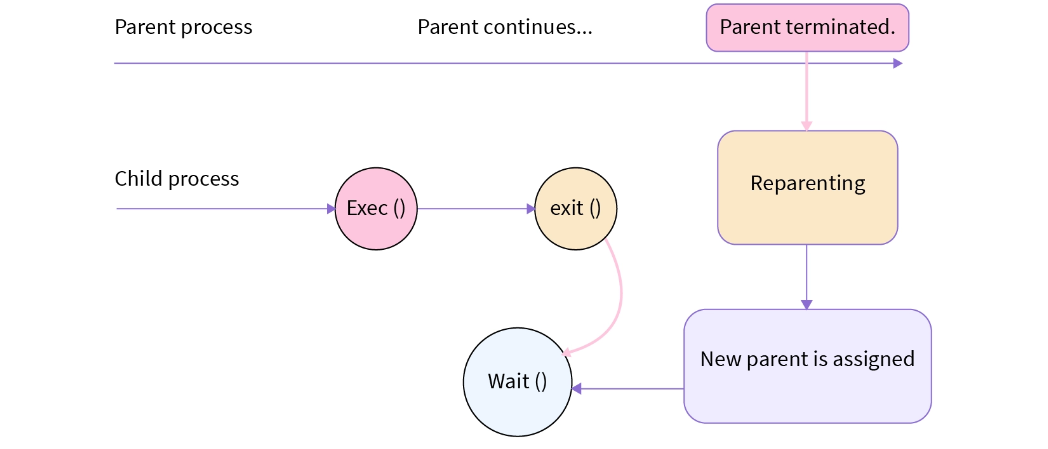
虽然init进程会接管孤儿进程,但是大量的孤儿进程会增加 init 进程的负担。而且孤儿进程可能会使调试变得复杂。为了更美好的明天,我们应尽量避免孤儿进程的产生。如果孤儿进程并不关键,我们可以用kill -SIGKILL [PID]杀死孤儿进程。(ꈨຶꎁꈨຶ)۶”
4.2 Zombie Process
当子进程先于父进程终止但父进程尚未调用 wait() 系统调用时,子进程会变成僵尸进程。僵尸进程的进程表项会保留在系统中,直到父进程读取其退出状态。如果父进程终止前一直不读取其状态,僵尸进程就会一直霸占进程表项资源。而进程表项的数量是有限的(通常为 65536 项)。

4.2.1 Process Table Entry
其实进程表项你已经很熟悉了,它就是PCB——进程控制块的别名。现在,我们还有一个疑问没有解决,那就是子进程变为僵尸进程后,为什么其 PCB 要父进程读取后才能释放?
之前我们学习 exit() 系统调用的时候看到,程序退出的系统调用实际上是没有返回值的。退出码会记录到 PCB 的 exit_code 字段中。一旦调用 exit() ,系统就会释放这个程序所携带的所有资源。随后子进程会变为僵尸进程并将其终止状态信息保留在PCB中。
终止状态信息包括退出退出码、终止信号、资源使用统计等信息。这些信息反映了子进程的运行时的状态、任务完成状态等。本着谁创建,谁回收的原则,僵尸进程需要父进程读取其PCB后,PCB才能被释放。父进程回收子进程的PCB需要用到 wait() 或 waitpid() 的系统调用。
4.2.2 wait() System Call
wait()系统调用会阻塞父进程,知道任意一个子进程终止。当子进程终止,wait()会返回子进程的PID,子进程的退出状态会被存储到父进程提供的地址中。
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait();
/*
Parameters: None.
Return value:
- On success: Returns the process ID (PID) of the terminated child process.
- On failure: Returns -1 and sets errno appropriately.
*/
waitpid() 是增强版的 wait()。它可以指定具体的子进程,还支持非阻塞模式(WNOHANG)。
pid_t waitpid(pid_t pid, int *status, int options);
/*
Parameters:
1. pid: The process ID of the child process to wait for. If pid is -1, wait for any child process.
2. status: Pointer to an integer where the exit status of the child process will be stored.
3. options: Options to modify the behavior of waitpid (e.g., WNOHANG).
Return value:
- On success: Returns the process ID (PID) of the terminated child process.
- On failure: Returns -1 and sets errno appropriately.
*/

当子进程用exit()系统调用终止执行后,内核会给父进程发送一个SIGCHLD信号(待会会用到),理想情况下,父进程应当读取子进程的信息并删除子进程的进程表项(process entry)。所以其实每个子进程执行结束都会变成僵尸进程,保留最小退出信息。

4.2.3 Fork Bomb : An Extreme Case
下面是一个fork炸弹,尽管在运行时不会产生僵尸进程,但是进程会源源不断地产生子进程,子进程又会源源不断的产生子进程,不一会儿你就会发现系统卡死了。这时,系统资源耗尽,无法再启动新进程,现有的进程可能会很慢甚至无法响应。
#include <unistd.h>
int main()
{
while(1)
fork();
return 0;
}
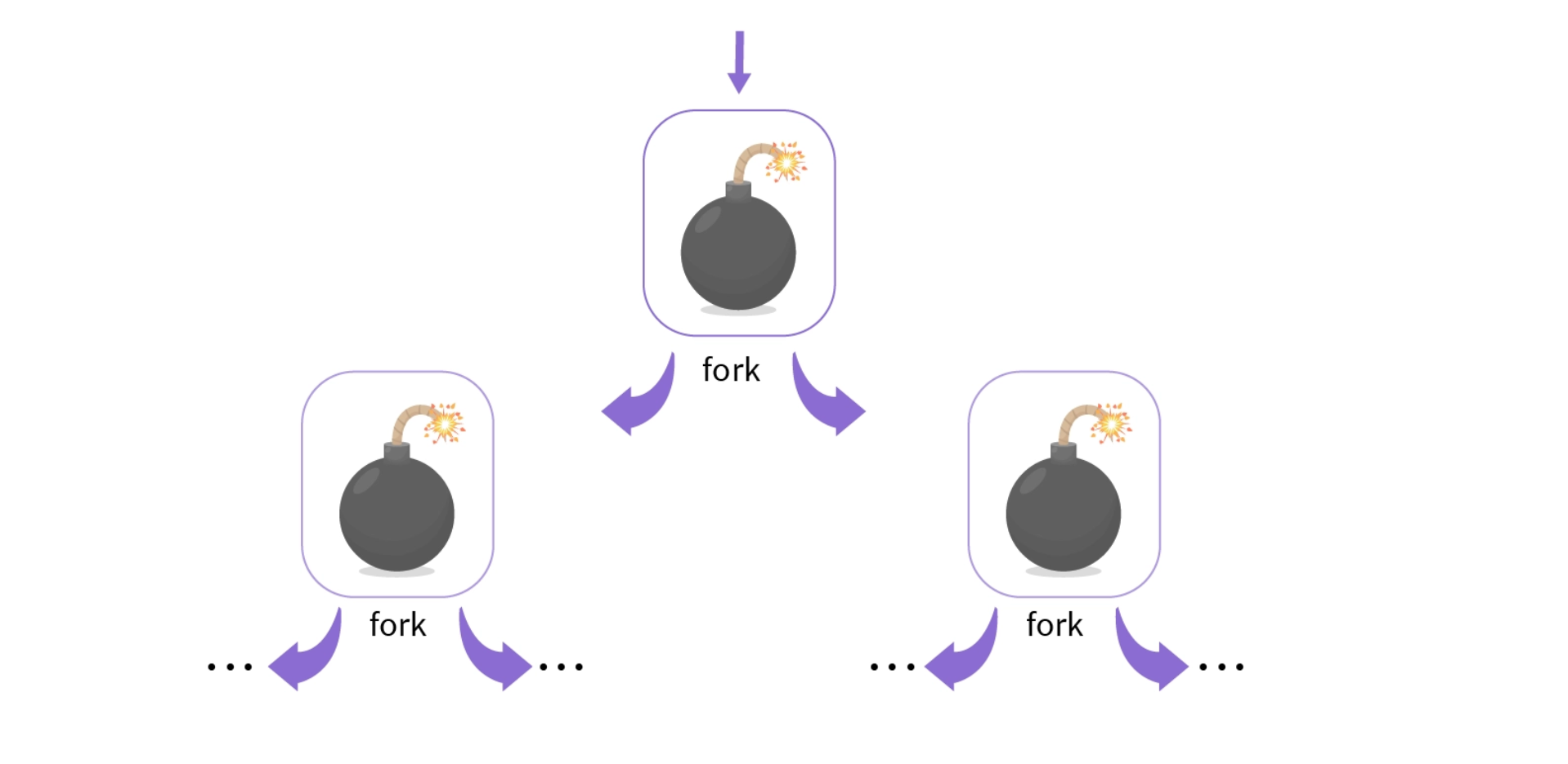
4.2.4 Zombie Maker
通过对上面的fork炸弹做一些修改,你可以用top命令来直观地查看该进程所产生的僵尸进程。这个例子中的子进程将不会再产生子进程,因而不会产生上面进程数量的指数爆炸,更加安全一些。每隔一秒,父进程就会fork一次,子进程会迅速结束并变成僵尸进程。
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdio.h>
int main() {
while(1){
pid_t pid = fork();
if (pid == 0) {
_exit(0);
} else {
// wait(NULL);
// printf("Child cleanup!\n");
printf("A zombie is made.\n");
sleep(1);
}
}
return 0;
}
我们前面说过,僵尸进程会占用系统的进程表项资源,而且这种资源是有限的。当所有PIDs都被僵尸进程霸占后,我们将不能够再创建新进程。在这种极端的情况下,我们只能够重启系统了。那如何解决这些僵尸进程呢?
最好的解决方案当然是编写正确的程序,确保子进程退出后父进程读取其进程表项。然而,犯错有时是难免的。在这个例子中,我们可以直接终止父进程,这样 init 进程会接管并清理掉这些僵尸进程。然而在实际中,我们并不能直接关闭服务器(用户还等着服务器提供服务呢),因此需要手动清理偶尔产生的僵尸进程。在学习信号时我们会讲到。
第x课 SIGCHILD
这里我们简单了解一下信号,为如何用信号处理僵尸进程做铺垫。作为进程间通信的一部分,我们将在进程间通信中详细探讨信号。
x.1 POSIX Signals
每个发送给进程的信号都有相应默认的处理程序(handler)。如果进程自己没有为特定信号注册相应的处理程序,那么收到信号时,就会执行默认的处理程序。下面举例了一些常用的 POSIX.1-1990 标准下的信号:
| Signal | Comment | Value | Action | Comment |
|---|---|---|---|---|
| SIGHUP | Hang-up detected | 1 | Term | Terninate process |
| SIGINT | Keyboard interrupt (Ctrl+C) | 2 | Term | Terninate process |
| SIGQUIT | Quit form keyboard | 3 | Core | Terminate and dump debug info |
| SIGILL | Illegal instruction | 4 | Core | Terminate and dump debug info |
| SIGKILL | Kill signal | 9 | Term | Terminate process |
| SIGSEGV | Segmentation fault | 11 | Core | Terminate and dump debug info |
| SIGTERM | Terminatation signal | 15 | Term | Terminate process |
| SIGCHLD | Child stopped or terminated | 20, 17, 18 | Ign | Ignore |
| SIGCONT | Continue if stopped | 19, 18, 25 | Cont | Continue if process stopped |
| SIGSTOP | Stop process | 18, 20, 24 | Stop | Stop process |
x.1.1 Handling Signals
如果进程想选择特立独行,想要接收到信号之后执行自定义的处理程序,对于大多数信号而言,这样是可行的,这样可以在信号触发时执行特定的逻辑。例如,当按下 Ctrl+C (SIGINT 信号) 时,进程可以执行一些清理操作或记录日志,而不仅仅是简单地终止进程。
对于任何事件发生的信号,信号都必须被响应处理,那怕在处理程序中什么都不做。此外,我们有两个特殊的信号 SIGKILL 和 SIGSTOP 不可以被捕获、阻塞或忽略。SIGKILL 信号用于强制终止进程,而 SIGSTOP 信号用于停止进程的执行。无论进程如何设置信号处理程序,这两个信号都会被内核直接处理,以确保系统能够对不响应的进程进行强制干预。
x.1.2 Taste the Blood
在命令行界面,我们常用 kill [PID] 命令来杀掉一个 PID 进程号的进程。通常情况下,使用 kill 8080 这样的命令会向8080号进程发送一个 SIGHUP 的信号,默认情况下,这个进程就会被终止(当然你可以注册另外的处理程序来进行额外的善后工作)。
如果进程仍然阻塞,你可以用 kill -9 8080 来强制终止这个进程。这个 -9 参数就是向进程发送9号信号(SIGKILL),而默认下是1号信号(SIGHUP)。
x.2 Zombocalypse Cleanup
在子进程退出时,父进程需要读取其进程表项以避免僵尸进程的出现。然而,尽管子进程终止后会像父进程发送SIGCHILD的信号,但是我们在上面看到,对于这个信号,默认的处理方式却是忽略。要避免僵尸进程的产生,我们的想法是在父进程收到子进程退出时发来的SIGCHILD信号后读取相应的进程表项。
x.2.1 Lock and Load
我们用下面的函数注册信号的服务例程,其中signo是想要捕获的信号号,后面的sig_handler是对该信号的服务例程。
// This is a void handler
void sig_handler(int signo){
/* Handle the signal in some way. */
}
// Register the handler
void (*signal(int signo, void(*sig_handler)(int))) (int);
x.2.2 Fire!!!
我们前面说过,要避免僵尸进程,我们就需要使父进程wait()子进程,但这一过程会阻塞父进程,这是我们不想要看到的。其实如果父进程结束,这些僵尸进程会被进程号为1的进程接管并自动释放资源,但是父进程可能是服务器,需要一直运行下去。
我们知道,当子进程运行结束,子进程就会给父进程发送SIGCHLD信号。我们可以让父进程捕捉这样的信号,然后在其中调用wait()系统调用,从而释放子进程的进程表项,即杀死僵尸进程:
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <signal.h>
#include <unistd.h>
void SIGCHLD_handler(int signo) {
while (waitpid(-1, NULL, WNOHANG) > 0){
printf("Released in SIGCHLD_handler!\n");
}
}
int main() {
signal(SIGCHLD, SIGCHLD_handler);
while (1) {
pid_t pid = fork();
if (pid == 0) {
printf("Hello from child process.\n");
sleep(1);
exit(0);
} else if (pid < 0) {
perror("fork failed");
exit(1);
}
//sleep(5); // Nonsense, program will wake up after handler being called.
}
return 0;
}
运行程序后,打开另一个终端。用命令ps -aux | grep 'Z'查看当前系统下的僵尸进程,应当每隔1秒钟就多一个僵尸进程。当我们用ctrl+c给进程发送SIGINT终止进程时,你会看到这些僵尸进程的资源都被释放掉了。如果你想子程序退出后立即释放,就将上面的注释删掉。
x.2.3 sigaction: Standardized Signal Handling
sigaction是一个规范的、扩展性更好的信号处理框架。
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <signal.h>
#include <unistd.h>
void SIGCHLD_handler(int signo) {
while (waitpid(-1, NULL, WNOHANG) > 0) {
printf("Released in SIGCHLD_handler!\n");
}
}
void SIGINT_handler(int signo) {
while (waitpid(-1, NULL, WNOHANG) > 0) {
printf("Released in SIGINT_handler!\n");
}
exit(0);
}
int main() {
struct sigaction sa;
sa.sa_handler = SIGCHLD_handler;
sigemptyset(&sa.sa_mask);
sa.sa_flags = SA_RESTART;
sigaction(SIGCHLD, &sa, NULL);
sa.sa_handler = SIGINT_handler;
sigemptyset(&sa.sa_mask);
sa.sa_flags = 0;
sigaction(SIGINT, &sa, NULL);
while (1) {
pid_t pid = fork();
if (pid == 0) {
printf("Hello from child process.\n");
sleep(1);
exit(0);
} else if (pid < 0) {
perror("fork failed");
exit(1);
} else {
printf("Child created!\n");
}
// sleep(5); // Nonsense, program will wake up after handler being called.
}
return 0;
}